Recogniform Workgroup Reader
 Recogniform Reader Versione Desktop Recogniform Reader Versione Desktop 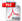 download brochure in formato.pdf download brochure in formato.pdf  richiedi informazioni richiedi informazioni
1. Descrizione
Recogniform Workgroup Reader è la naturale evoluzione di Recogniform Desktop Reader, di cui conserva intatte la maggior parte delle caratteristiche, ma rispetto a ques'ultimo consente di operare in architettura distribuita
invece che su singola postazione.
Gli applicativi di cui Recogniform Workgroup Reader si compone sono:
 La configurazione può essere effettuata in modo che vi siano più stazioni di lavoro di un certo tipo, in base alle esigenze applicative. Ad esempio se la correzione richiede più risorse, è possibile utilizzare stazioni di correzione multiple, così come se si dispone di più scanners è possibile usare stazioni di input multiple. La configurazione può essere effettuata in modo che vi siano più stazioni di lavoro di un certo tipo, in base alle esigenze applicative. Ad esempio se la correzione richiede più risorse, è possibile utilizzare stazioni di correzione multiple, così come se si dispone di più scanners è possibile usare stazioni di input multiple.
Il sistema di licensing prevede la possibilità di utilizzare un qualsiasi numero di stazioni di input, correzione ed output senza dover pagare costi aggiuntivi.
La comunicazione tra le stazioni ed il server è basata su protocollo TCP/IP per cui tutto può funzionare anche su Internet, consentendo la dislocazione remota degli applicativi. Una delle possibili applicazione
è la possibilità di avere degli operatori che effettuanola correzione remota da casa, operando il tele-lavoro. Altra applicazione è la possibilità di effetturare l'acquisizione dei moduli cartacei da remoto, senza mai spostarli fisicamente dal luogoin cui sono custoditi per poter essere lavorati.
Infatti mentre con la versione Desktop tutte le funzionalità sono disponibili su una singola postazione, nella versione Workgroup le funzionalità di acquisizione, riconoscimento, verifica, correzione ed output vengono suddivise su postazioni diverse specializzate.
1.1 Ambiti di applicazione
Grazie alla sua flessibilità, Recogniform Reader si presta ad infinite possibilità di utilizzo. Eccone alcune:
|
Lettura ottica questionari di ogni tipoLettura ottica test d'ingresso
Lettura ottica schede di valutazioneLettura ottica moduli richiesta carta fedeltà Lettura ottica cartoline di registrazione
Lettura ottica certificati di garanzia
|
Lettura ottica questionari customer satisfactionLettura ottica form selezione del personaleLettura ottica ricette farmaceutiche SSN
Lettura ottica bollettini
Lettura ottica fatture e bolle (vedi Recogniform INVOICES)Lettura ottica di qualsiasi documento strutturato e semi-strutturato
|
1.2 Tecnologia
Recogniform Reader integra le più avanzate tecnologie:
tagliare ed estrapolare intere pagine o parti di esse ed archiviarle come immagini in formato digitale: IDE
rendere operativo l'inserimento manuale assisito (da immagine) di dati: AMK
1.3 Fasi di lavorazione
Le operazioni di lettura ottica ed estrazione dei dati possono essere distinte in quattro fasi principali:
1. Acquisizione
2. Riconoscimento
3. Validazione / correzione
4. Output
Una quinta fase, propedeutica alle quattro fasi di "produzione" in senso stretto appena indicate, è relativa alla definizione del template. Cos'è un template? Un "template" è l'insieme delle "regole" necessarie ad indicare al sistema cosa leggere e dove (ad esempio: codice a barre di tipo Code39 nell'area del modulo in alto a destra).
Definire un template è molto semplice: grazie alla pratica interfaccia visuale del modulo Recogniform Application Designer (incluso in Recogniform Reader), è sufficiente disegnare i campi sul modulo vuoto ed indicare la natura del dato da estrarre. Inoltre, mediante un potente e flessibile linguaggio di scripting interno, è possibile implementare funzioni e procedure estremamente personalizzate, in grado di soddisfare anche i "tecnici" ed i clienti più esigenti.
2. Acquisizione delle immagini: Recogniform Input Station
Recogniform Workgroup Reader consente di effettuare la lettura ottica di documenti acquisiti in diversi modi:
-
scanner
- files
- monitoraggio directory
- internet
- fax
Possono essere usate non solo immagini monocromatiche ma anche quelle a toni di grigio ed a colori: in quest'ultimo caso il sistema può eliminare la fincatura colorata attraverso una procedura software, con risultati addirittura superiori a quelli raggiunti via hardware usando le drop-ink lamp.
2.1 Acquisizione da scanner
Sono supportati direttamente tutti gli scanner dotati di driver TWAIN. L'acquisizione automatica dei documenti (ADF)anche fronte/retro, le drop-ink lamp e le schede di elaborazione delle immagini per il dynamic thresholding non sono un problema! Ciò significa che si può scegliere liberamente
lo scanner più adatto alle proprie esigenze:
da quello
più
semplice ed economico (capace di acquisire solo pochi fogli
al minuto), a quello più sofisticato, caratterizzato da un'elevata produttività e capace di elaborare centinaia di fogli al minuto.
2.2 Acquisizione da files
Recogniform Workgroup Reader consente anche di elaborare immagini precedentemente acquisite ed archiviate come file in formato TIFF non compresso o in un qualsiasi formato compresso (CCITT G4, CCITT G3, Huffman, PAckbits, JPeg), a pagina singola o multipla,
così come in formato JPEG, BMP, PNG, PDF.
2.3 Acquisizione mediante monitoraggio automatico di una directory (con o senza sottodirectory)
Una comoda possibilità è quella di avviare il monitoraggio di una directory, importando automaticamente i files che vi vengono salvati da altre applicazioni, inziando la lavorazione ion automatico o al raggiungimento di un certo numero di forms, o ad intervalli temporali predefiniti.
2.4 Acquisizione da internet
Il supporto di Internet è garantito attraverso la possibilità di scaricare automaticamente le immagini da elaborare da  qualsiasi server. Infatti, usando il protocollo FTP, un ID ed una password, i file remoti possono essere velocemente scaricati in tutta sicurezza. Ciò significa che l'acquisizione tramite
scanner può essere effettuata in un posto differente
da quello in cui si svolge l'operazione di lettura ottica: la realizzazione di applicazioni geograficamente distribuite è supportata in modo semplice e naturale. qualsiasi server. Infatti, usando il protocollo FTP, un ID ed una password, i file remoti possono essere velocemente scaricati in tutta sicurezza. Ciò significa che l'acquisizione tramite
scanner può essere effettuata in un posto differente
da quello in cui si svolge l'operazione di lettura ottica: la realizzazione di applicazioni geograficamente distribuite è supportata in modo semplice e naturale.
2.5 Acquisizione da fax
Anche l'acquisizione da fax è direttamente supportata, senza ricorrere all'ausilio di prodotti esterni. Abilitando la modalità di ricezione automatica dei fax ed usando un comune fax-modem, Recogniform Workgroup Reader, posto in modalità stand-alone, riceve, standardizza e rende disponibili per la lettura ottica ogni tipo di fax, con qualità standard o ad alta risoluzione.
3. Pre-processing delle immagini e riconoscimento ottico:
Recogniform Recognition Station
La forza di Recogniform Workgroup Reader risiede nell'uso di sofisticati motori di lettura che possono essere usati e combinati insieme secondo le specifiche dell'utente.
- CHR - Riconoscimento del corsivo manoscritto
Consente di leggere dati scritti a mano in corsivo (manoscritto non in stampatello): quello che era solamente immaginazione, adesso è realtà! Questa caratteristica è essenziale per leggere moduli che non sono stati espressamente progettati per l'acquisizione automatica
e che quindi contengono
campi non incasellati, scritti liberamente, senza alcun vincolo grafico.
- ICR - Riconoscimento Intelligente dei caratteri
Con questo sistema è possibile riconoscere dati manoscritti in forma incasellata e non incasellata quando c'è in genere spazio tra i caratteri. Il motore di lettura è stato espressamente addestrato sulla scrittura europea ed americana per ottenere un'elevata accuratezza.
- OCR - Riconoscimento ottico di caratteri.
È la tecnologia di riconoscimento per testi stampati o scritti a macchina. È "omnifont" e può riconoscere dati scritti con qualsiasi stile e misura.
- OCR - A/B/MICR - Riconoscimento ottico dei font OCRA, OCRB, E13B. CMC7
Questo motore di riconoscimento lavoro con codeline prestampate OCRA, OCRB, E13B, CMC7 di documenti postali e bancari.
- OMR - Riconoscimento ottico delle marchiature
È una tecnologia che consente di leggere le check box, ossia i segni affissi in spazi predefiniti. Il motore di riconoscimento è differente da quelli di prodotti similari, perché possiede il vantaggio di lavorare con due parametri operativi,
valutando la quantità d'inchiostro presente
e la misura del segno nella casella.
- BCR - Riconoscimento dei codici a barre
Consente di riconoscere i codici a barre, decodificandone il contenuto. Viene riconosciuto l'intero insieme di codici a barre, inclusi quelli farmaceutici.
- AMK - Digitazione manuale assistita
Consente di fare l'inserimento dei dati in modo manuale assistito per quei contenuti che non si vuole o non si può leggere in modo automatico.
- IDE - Esportazione di dati in forma di immagine.
Attraverso questo sistema è possibile esportare zone o intere pagine in formato immagine. È utile quando si devono mettere in archivio porzioni di moduli contenenti firme, schizzi, disegni o altre informazioni, senza modificare alcunché
delle loro caratteristiche.
- Free-Form and Layout Analysis
Consente di identificare un campo in base ad alcuni attributi specifici, quali ad esempio la sua etichetta, la sua formattazione, il suo layout grafico.
- Form-Identification
Consente di identificare un modulo o una pagina sulla sco
3.1 L'importanza del pre-processing
Un'adeguata e preventiva elaborazione dell'immagine aumenta la qualità del processo di riconoscimento e riduce l'ampiezza dei file. Per questo Recogniform Reader incorpora molteplici funzioni che coprono ogni specifica esigenza.
3.1.1 Pre-processing a livello "globale" (intera immagine):
-
Deskew
Correzione della pendenza causata talvolta dallo scanner quando acquisisce in modo automatico (ADF).
- Rimozione del bordo scuro
Rimozione dell'eventuale bordo scuro dovuto all'eccessiva estensione dell'area di scanning.
-
Auto orientamento
consente al sistema di auto-orientare i moduli acquisiti ruotandoli di 90, 180 o 270 gradi in modo che combacino con l'orientamento del template.
-
Allineamento del modulo e rimozione
Allineamento del modulo per compensare un eventuale spostamento orizzontale o verticale e rimozione della parte prestampata quando il modulo non è stampato con inchiostro cieco.
3.1.2 Pre-processing a livello "locale" (singola area di lettura definita):
-
Deskew
Correzione dell'inclinazione dell'area, magari perchè si tratta di una etichetta incollata.
-
Rimozione delle linee
Rimozione delle linee orizzontali e verticali con ricostruzione dei caratteri da esse attraversati.
-
Despeckle
Rimozione dei punti neri isolati.
-
Smooth
Ricostruzione di caratteri ed elementi rovinati.
-
Rimozione degli elementi di delimitazione dei campi
Rimozione degli elementi di delimitazione (rettangoli, semi-rettangoli, ecc.), utile se questi non sono stampati con inchiostro cieco.
-
Rimozione delle caselle
Rimozione delle caselle che contengono i singoli caratteri nei campi incasellati, utile se queste non sono stampate con inchiostro cieco.
-
Inversione del colore
Inversione del colore in caso di caratteri bianchi su sfondo scuro.
-
Rimozione delle intrusioni
Rimozione degli elementi di disturbo (stalattiti, stalagmiti) che fanno parte di campi vicini.
-
Rimozione elementi grandi o piccoli
Rimozione degli elementi troppo grandi o troppo piccoli, con soglia definibile a piacere.
-
Assottigliamento o Inspessimento
Normalizzazione del tratto della penna usata per scrivere.
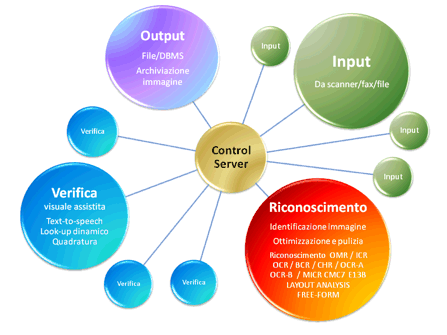
4. Validazione e correzione: Recogniform Correction Station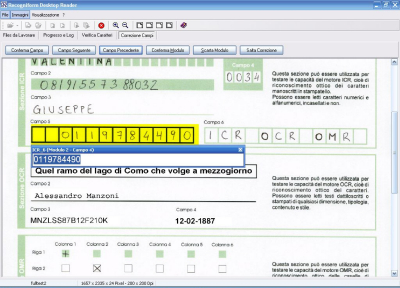
È possibile decidere quali campi necessitino correzione: tutti; solo quelli il cui livello di accuratezza stimata è inferiore ad una certa soglia; nessuno. E' inoltre possibile effettuare controlli "al volo", sia durante la fase di riconoscimento
che di correzione, in modo da auto-validare alcuni campi sulla base
di un insieme di regole da definire. Ad esempio, qualora in un modulo contenente dati anagrafici il codice fiscale risultasse corretto sulla base del check-digit, si potrebbe settare i valori del campo "data di nascita" attingendo gli stessi dal codice fiscale corretto, bypassando di fatto la fase di correzione.
4.1 Trigrammi
Usando il nuovo sistema di correzione e convalida basato sui trigrammi, può essere verificata la maggior parte dei campi alfabetici ed è possibile risolvere tutti i dubbi generati da riconoscimenti ambigui in modo pienamente automatico. Questo sistema usa informazioni statistiche relative a tutte le possibili combinazioni di tre caratteri consecutivi nel linguaggio preso
come target; queste combinazioni sono chiamate trigrammi
e sono
raccolte analizzando alcune migliaia di parole e predisposte
pronte per essere usate: in questo modo tutte le combinazioni di trigrammi, quelle consentite e quelle proibite, così come la loro frequenza di utilizzo sono pienamente e chiaramente note. Per esempio, se un motore di riconoscimento legge la parola "SMITK" , il sistema correggerà questa parola mutandola in "SMITH", senza l'intervento di un operatore e senza il rischio di un risultato errato! Infatti, usando una nuova tecnologia chiamata CREP (Common Recognition Errors Proofing), Recogniform
Workgroup Reader, con l'aiuto di un sistema di Intelligenza Artificiale, è capace, in piena autonomia, di investigare tutte le combinazioni dimostrabili e di selezionare quella più probabile.
4.2 E.B.V.® (Eye Blow Verification)
 In fase di definizione dell'applicazione, è possibile fare in modo che i caratteri manoscritti o quelli provenienti dalle codeline (tutti o solo quelli sospetti, il cui livello di confidenza è inferiore ad una specifica soglia parametrica) siano presentati ad
un operatore per una verifica visuale. Anche in questa fase Recogniform Workgroup Reader mostra le sue nuove caratteristiche: infatti grazie all'esclusivo sistema chiamato Eye Blow Verification®, un operatore può verificare migliaia di caratteri al minuto con il minimo sforzo e con grande accuratezza. Questo sistema è basato sul principio che, nell'ambito di un gruppo di elementi simili, l'occhio è automaticamente attratto da quelli differenti. Per esempio, se in un gruppo di persone ognuno indossa una
camicia
blu ad eccezione di una persona che ha una camicia rossa, quest'ultimo sarà notato rapidamente senza una dettagliata analisi dell'intero gruppo! In base a queste considerazioni, Recogniform Workgroup Reader raggruppa nello stesso contesto tutte le immagini dei caratteri riconosciuti e classificati nello stesso modo, così un operatore può osservare ed avvertire la presenza di intrusi, la cui forma e differente da quella degli altri, generati da una classificazione errata. In questo modo è possibile trovare e correggere
tutti i possibili errori di riconoscimento introdotti da: sporco non eliminabile, difetti di scanning, ambiguità, ecc.Ed anche quando siamo di fronte a casi di ambiguità, Recogniform Workgroup Reader consente istantaneamente di risolvere il problema, richiamando automaticamente sul video l'immagine dell'intero campo. In fase di definizione dell'applicazione, è possibile fare in modo che i caratteri manoscritti o quelli provenienti dalle codeline (tutti o solo quelli sospetti, il cui livello di confidenza è inferiore ad una specifica soglia parametrica) siano presentati ad
un operatore per una verifica visuale. Anche in questa fase Recogniform Workgroup Reader mostra le sue nuove caratteristiche: infatti grazie all'esclusivo sistema chiamato Eye Blow Verification®, un operatore può verificare migliaia di caratteri al minuto con il minimo sforzo e con grande accuratezza. Questo sistema è basato sul principio che, nell'ambito di un gruppo di elementi simili, l'occhio è automaticamente attratto da quelli differenti. Per esempio, se in un gruppo di persone ognuno indossa una
camicia
blu ad eccezione di una persona che ha una camicia rossa, quest'ultimo sarà notato rapidamente senza una dettagliata analisi dell'intero gruppo! In base a queste considerazioni, Recogniform Workgroup Reader raggruppa nello stesso contesto tutte le immagini dei caratteri riconosciuti e classificati nello stesso modo, così un operatore può osservare ed avvertire la presenza di intrusi, la cui forma e differente da quella degli altri, generati da una classificazione errata. In questo modo è possibile trovare e correggere
tutti i possibili errori di riconoscimento introdotti da: sporco non eliminabile, difetti di scanning, ambiguità, ecc.Ed anche quando siamo di fronte a casi di ambiguità, Recogniform Workgroup Reader consente istantaneamente di risolvere il problema, richiamando automaticamente sul video l'immagine dell'intero campo.
4.3 Correzione Visuale Assistita
Dopo la fase di verifica dei caratteri inizia la fase di "correzione" vera e propria, con la visualizzazione nello stesso contesto sia dei dati che della relativa immagine, in modo da confrontarli direttamente.

4.3.1 Text-To-Speech
Per ridurre il tempo che l'operatore necessita per fare l'analisi comparativa dei dati letti e dei dati originali nell'immagine, abbiamo aggiunto un'opzione che consente di ascoltare dal computer i dati letti attraverso l'uso della tecnologia text-to-speech: in questo modo, invece di leggere i dati due volte, l'operatore può leggere una sola volta dall'immagine, ascoltando dal computer gli altri dati acquisiti.
4.3.2. Normalizzazione dei dati
Prima di essere archiviati, i dati letti possono essere formattati in diversi modi, consentendo di adattare l'output ad ogni necessità: conversione in maiuscolo o minuscolo; eliminazione degli spazi vuoti; sostituzione di caratteri; aggiunta di suffissi o prefissi; ecc.
4.3.3. Tabelle di lookup e vocabolari compressi
Oltre ai vari formati di database ed ai files txt è anche possibile usare i dizionari compressi .dct che consentono una maggiore velocità di accesso, una minore occupazione di memoria e non richiedono settings di alias, etc.. Per creare un file .dct è stata preparata una apposita utility che prende in input un file di testo ASCII, con una parola per riga, generando un file DCT.
La velocità di look-up è estrema, nell' ordine delle centinaia di migliaia di confronti al secondo. La compressione è elevatissima, nell' ordine di milioni di parole per Mb.
Forniamo dizionari già pronti in formato DCT con Nomi, Cognomi, Strade, CAP, Comuni, Province, Regioni, Prefissi telefonici e principali e-mail providers per i seguenti Stati:
- Italia
- Belgio
- Finalandia
- Francia
- Germania
- Gran Bretagna
- Olanda
- Polonia
- Portogallo
- Spagna
- Svizzera
- Turchia
- U.S.A.
Altri dizionari sono disponibili su richiesta. Inoltre è possibile creare dizionari personalizzati.
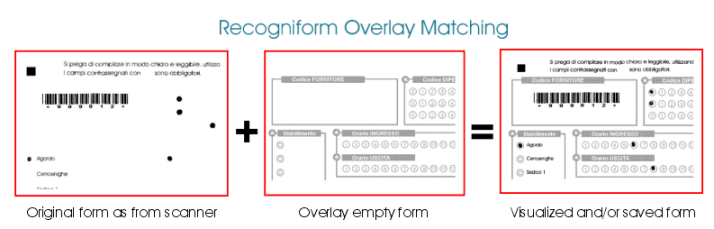
4.3.4. Overlay
A partire dalla versione 8.0 di Recogniform Reader è possibile utilizzare la nuova funzionalità di Overlay, che consente di visualizzare in fase di correzione il modulo opportunamente "ricostruito". Ciò avviene sovrapponendo l'immagine acquisita dallo scanner ad un modulo vuoto, in cui è visibile la fincatura filtrata via scanner. La sovrapposizione avviene tenendo conto di eventuali skew, stretch, offset verticale e/o orizzontale, in modo da rappresentare fedelmente il modulo originale. Utilizzare
il modulo di overlay è semplice: basta indicare il nome del file da utilizzare come "sfondo" e decidere se utilizzare questa funzionalità solo in fase di correzione a video o anche in fase di output, così da salvare su disco l'immagine ricostruita.
5. Output dei dati
Recogniform Workgroup Reader consente un uso flessibile dei dati riconosciuti grazie alla possibilità di esportarli esternamente all'applicazione in differenti formati. È possibile esportare dati con tre differenti metodi: verso database, verso file, verso applicazioni.
|
Sono interfacciati tutti i database:
- Oracle
- Interbase
- Sybase
- Microsoft SQL Server
- DB2
- Paradox
- dBase
- FoxPro
- Access
- ODBC compatibili
|
I formati dei file supportati per l'output sono:
- Testo ASCII (.txt)
- Testo con spaziature fissa (.asc)
- Comma Separed Value (.csv)
- Tab Separed Value (.tsv/.tab),
- Hypertest Markup Language (.htm/.html)
- Extensible Markup Language (.xml)
- Microsoft Excel (.xls)
- Symbolic Link Interchange Format (.slk/.sylk)
- Comandi SQL (.sql)
- dBase (.dbf)
- Paradox (.db)
- Access (.mdb)
- Portable Document Format (.pdf)
|
Oltre ai vari formati dati, è ora disponibile anche un formato misto "immagini + dati" che consente di creare in output un singolo file PDF ricercabile, cioè un file in cui alle immagini lavorate viene sovrapposto il testo riconosciuto: il testo non è volutamente visibile, ma è ricercabile e può essere anche copiato ed incollato. Può essere molto utile per creare
degli archivi di documenti omogeni in formato PDF autonomi, con le immagini originali scandite e con i dati riconosciuti o digitati per indicizzazione.
Vi è inoltre la possibilità di inserire un prefincato da sovrapporre all' output in PDF, utilissima per ricostruire il modulo originario qualora la scansione sia avvenuta in modulo cieco. I formati di file supportati per le immagini in output sono:
Recogniform Workgroup Reader può anche direttamente inviare i dati ad altre applicazioni, usando alcuni script di funzioni che consentono di emulare l'input dell'operatore da tastiera.
6. Recogniform Control Server
Recogniform Control Server è il cuore del sistema, è l'applicativo che gestisce e coordina lo scambio di informazioni e dati tra le varie stazioni. Si tratta di un'applicazione che
lavora in modo autonomo, senza operatore, mettendo comunque a disposizione dell'amministratore del sistema tutta una serie di informazioni relative alle elaborazioni in corso ed al loro stato.
Il Control Server tiene traccia quindi dello stato di lavorazione di ogni batch, ne centralizza l'archiviazione e ne gestisce il workflow.Ciò è possibile perchè l'approccio utilizzato è job-oriented, raggruppando i documenti per lotti: un lotto (batch) può contenere un numero qualsiasi di documenti (da 1 a "n") ed il lavoro in ogni batch si articola nelle seguenti fasi:
-
acquisizione delle immagini (da scanner o da file);
-
pre-processing (deskew,despeckle, form removal, etc.)
-
lettura automatica (CHR, OCR, ICR, BCR, OMR, etc.)
-
verifica dei caratteri sospetti (Eye Blow Verification®)
-
correzione dei campi (analisi comparativa tra immagine e dati);
-
post-processing (trasformazione dei dati e normalizzazione);
-
output dei dati (archiviazione in file e database).
7. Personalizzazione attraverso gli script
Recogniform Workgroup Reader consente di settare l'intero insieme di parametri necessari per la lettura ottica dei dati in modo visuale. Inoltre è dotato di un sofisticato linguaggio di scripting orientato agli eventi, adatto a soddisfare particolari esigenze. Questo linguaggio consente di associare una specifica procedura scritta dall'utente ad ogni evento schedulato, modificando il comportamento standard del
programma
o integrando nuove caratteristiche. È molto simile al Basic e al Pascal, quindi è molto semplice a imparare ed usare. Questo linguaggio include le espressioni condizionali (IF), i cicli (FOR, REPEAT, WHILE) nella sua sintassi ed usa migliaia di funzioni integrate. Il sistema può settare automaticamente specifiche variabili, consentendo un'efficace interazione tra l'applicazione ed il processo di riconoscimento ottico.
Questa caratteristica offre la possibilità di implementare personalizzazioni quali i controlli di quadratura tra i campi, le letture multiple dello stesso campo con differenti opzioni di pre-processing, od output e layout personalizzati. Con questo sistema si può ottenere un'applicazione fortemente personalizzata partendo da un prodotto standardizzato. I vantaggi
sono chiari:
costi ridotti e migliore affidabilità e flessibilità.
8. Statistiche
Recogniform Workgroup Reader consente di registrare automaticamente tutti i dati statistici relativi ad ogni elaborazione in un file di log, che può essere centralizzato in caso di installazioni multiple.
Le informazioni immagazzinate sono:
-
data ed ora d'inizio;
-
nome dell workstation;
-
User name;
-
tipo di modulo;
-
durata della lettura automatica;
-
durata del tempo di verifica dei caratteri;
-
durata della fase di correzione dei campi;
-
numero di moduli elaborati;
-
numero di campi letti correttamente;
-
numero di campi sospetti;
-
numero di campi corretti;
-
numero di caratteri letti correttamente;
-
numero di caratteri sospetti;
-
numero di caratteri corretti.
Usando il modulo Recogniform Statistics Viewer, è possibile analizzare i dati in modo automatico, ottenendo, su video o su carta, grafici dettagliati contenenti informazioni significative sulla produttività.
I grafici possono essere relativi a tutte le elaborazioni o ad una elaborazione in particolare. Essi mostrano:
-
il numero di moduli elaborati per workstation;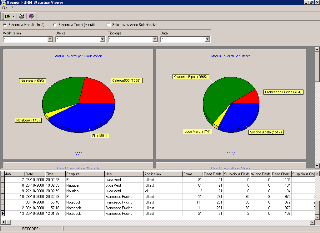
-
il numero di moduli processati per utente;
-
il numero di moduli processati al giorno;
-
il numero di moduli processati per tipologia;
-
tempo di elaborazione di ogni workstation;
-
tempo di elaborazione per ogni utente;
-
Tempo di elaborazione giornaliero
-
tempo di elaborazione per ogni tipologia;
-
Distribuzione del tempo tra lettura, verifica e correzione;
-
totale dei caratteri letti, sospetti e corretti;
-
totale dei campi letti, sospetti e corretti.
È anche possibile usare filtri per analizzare solo dati relativi ad unaworkstation e/o ad un utente e/o ad una tipologia e/o ad una giornata. I dati statistici possono essere esportati anche in file .cvs per essere analizzati con altre applicazioni. In sintesi, con questo sistema è possibile monitorare la produttività e le statistiche degli utenti in modo globale e dettagliato.
© 2000-2022 Recogniform Technologies S.p.A.
|
