Recogniform Reader
 Versione Desktop Versione Workgroup Recogniform Invoices Versione Desktop Versione Workgroup Recogniform Invoices  download brochure in formato.pdf download brochure in formato.pdf  info info
Descrizione
Recogniform Reader è la soluzione innovativa per la lettura ottica da moduli cartacei. Spesso infatti l'inserimento manuale dei dati rappresenta il collo di bottiglia nei processi di elaborazione dei moduli e di archiviazione dei documenti: paragonato all'inserimento manuale dei dati, infatti, il nostro sistema di data-capture consente di usare un ridotto numero di risorse umane, migliorando
efficienza e prestazioni, riducendo altresì gli errori causati dall'affaticamento del personale. Quindi
meno costi, più velocità, più qualità costante nel tempo.
Ambiti di applicazione
Grazie alla sua flessibilità, Recogniform Reader si presta ad infinite possibilità di utilizzo. Eccone alcune:
|
Lettura ottica questionari di ogni tipoLettura ottica test d'ingresso
Lettura ottica schede di valutazioneLettura ottica moduli richiesta carta fedeltà Lettura ottica cartoline di registrazione
Lettura ottica statini d'esame
Lettura ottica schede rilevazione produzione
|
Lettura ottica questionari customer satisfactionLettura ottica form selezione del personaleLettura ottica ricette farmaceutiche SSNLettura ottica contratti / moduli prestazione consenso, etc.
Lettura ottica bollettini, fatture, bolle, ordini
Lettura ottica e classificazione documenti eterogenei
Lettura ottica di qualsiasi documento strutturato e non
|
Tecnologia
Utilizzando le più avanzate tecnologie, Recogniform Reader integra le seguenti tecnologie:
- Tecnologia OMR: Caselle di marchiatura (check box);
- Tecnologia ICR: Dati alfabetici, numerici ed alfanumerici manoscritti in stampatello, sia incasellati che non;
- Tecnologia BCR: Qualsiasi tipo di codice a barre;
- Tecnologia OCR: Testo stampato con caratteri tipografici di qualsiasi dimensione e font;
- Tecnologia
OCR-A: Codeline standard con numeri e simboli stampati con font OCR-A;
- Tecnologia
OCR-B: Codeline standard con numeri e simboli stampati con font OCR-B;
- Tecnologia CHR: Campi alfabetici, numerici e alfanumerici scritti a mano in corsivo;
- Tecnologia FREE-FORM e ANALISI del LAYOUT: Identificazione dinamica dei campi su documenti semi-strutturati o non strutturati;
- Tecnologia FORM IDENTIFICATION: Identificazione grafica del documento, ordinamento pagine, etc.;
- Tecnologia IDE: Ritaglio ed estrapolazione di intere pagine o parti di esse con archiviazione in formato digitale;
- Tecnologia AMK: Inserimento manuale assisito (da immagine) di dati.
Fasi di lavorazione
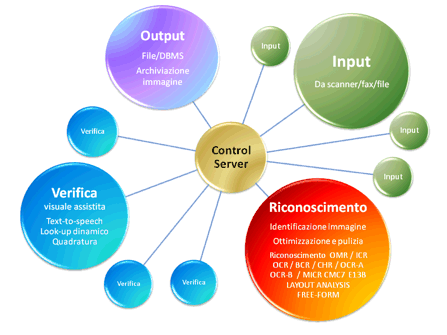
Le operazioni di lettura ottica ed estrazione dei dati possono essere distinte in quattro fasi principali:
1. Acquisizione
2. Riconoscimento
3. Validazione / correzione
4. Output
Una quinta fase, propedeutica alle quattro fasi di "produzione" in senso stretto appena indicate, è relativa alla definizione del template. Cos'è un template? Un "template" è l'insieme delle "regole" necessarie ad indicare al sistema cosa leggere e dove (ad esempio: codice a barre di tipo Code39 nell'area del modulo in alto a destra; oppure P.IVA in qualsiasi
area della pagina, in prossimità delle etichette "P.IVA" o "PARTITA IVA").
Definire un template è molto semplice: grazie alla pratica interfaccia visuale del modulo Recogniform Application Designer (incluso in Recogniform Reader), è sufficiente disegnare i campi sul modulo vuoto ed indicare la natura del dato da estrarre. Inoltre, mediante un potente e flessibile linguaggio di scripting interno, è possibile implementare funzioni e procedure estremamente personalizzate, in grado di soddisfare anche i "tecnici" ed i clienti più esigenti.
Desktop o Workgroup?
Recogniform Reader è disponibile in due versioni, in base alla modalità di esecuzione delle fasi appena citate:
-
Versione Desktop: tutte le fasi di elaborazione (acquisizione, riconoscimento, correzione ed output) vengono eseguite sulla stessa postazione, in modo sequenziale. Ideale per volumi di lavoro non troppo elevati, è l'alternativa al data-entry manuale per lavorazioni frequenti ma quantitativamente non eccessive.
-
 Versione Workgroup: le funzionalità di acquisizione, riconoscimento, correzione ed output vengono suddivise su postazioni diverse specializzate
secondo un'architettura distribuita client/server. La configurazione può essere effettuata in modo che vi siano più stazioni di lavoro di un certo tipo, in base alle esigenze applicative. Ad esempio, se la correzione richiede più risorse, è possibile utilizzare stazioni di correzione multiple, così come se si dispone di più scanners è possibile usare più stazioni di input. Versione Workgroup: le funzionalità di acquisizione, riconoscimento, correzione ed output vengono suddivise su postazioni diverse specializzate
secondo un'architettura distribuita client/server. La configurazione può essere effettuata in modo che vi siano più stazioni di lavoro di un certo tipo, in base alle esigenze applicative. Ad esempio, se la correzione richiede più risorse, è possibile utilizzare stazioni di correzione multiple, così come se si dispone di più scanners è possibile usare più stazioni di input.
La comunicazione tra le stazioni ed il server è basata su protocollo TCP/IP per cui tutto può funzionare anche su Internet, consentendo la dislocazione remota degli applicativi. Una delle possibili applicazioni è l'opportunità di avere degli operatori che effettuano la correzione remota da casa, operando il tele-lavoro. Altra applicazione è la possibilità di effetturare l'acquisizione dei moduli cartacei
da
remoto, senza mai spostarli fisicamente dal luogo in cui sono custoditi. Recogniform Workgroup Reader è la soluzione ideale per i centri di servizio, le Università, gli Enti governativi e per tutte le aziende con volumi consistenti o modulistica differenziata.
In entrambe le versioni l'approccio del sistema è di tipo job-oriented: ciò significa che la lavorazione avviene raggruppando i documenti per lotti (batch). Un batch può contenere un numero qualsiasi di documenti, e la sua attività ricalca le fasi di produzione anzidette, ovvero:

- - acquisizione delle immagini (da scanner o da file);
- - pre-processing (deskew,despeckle, form removal, etc.)
- - lettura automatica (CHR, OCR, ICR, BCR, OMR, etc.)
- - verifica dei caratteri sospetti (Eye Blow Verification®)
- - correzione dei campi (analisi comparativa tra immagine e dati);
- - post-processing (trasformazione dei dati e normalizzazione);
- - output dei dati (archiviazione su file e/o database).
Caratteristiche in sintesi
Al fine di sintetizzare le numerose e potenti caratteristiche di Recogniform Reader è conveniente seguire un approccio "per fasi", dalla fase di definizione del template alle fasi di "produzione" in senso stretto: acquisizione, riconoscimento, validazione/correzione e output. Per maggiori dettagli su aspetti tecnici e funzionalità, si
rinvia
alla pagine specifiche di Recogniform Desktop e Recogniform Workgroup Reader.
Fase 0. Definizione del template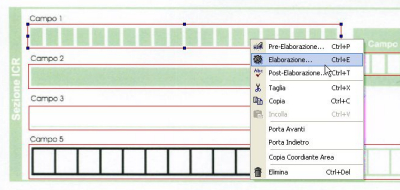
-
Definizione aree di lettura*
-
Semplice interfaccia visuale
-
Definizone parametri globali modulo
-
Definizone parametri di pre-elaborazione campo
-
Definizone parametri di elaborazione campo
-
Definizone parametri di post-elaborazione campo
- Personalizzazione via script
- Possibilità di implementare DLL esterne
- Procedure e regole di riconoscimento/correzione
- Utilizzo di moduli pre-esistenti NON ottimizzati per la lettura ottica: SI
* per l'elaborazione di modulistica semi-strutturata (documenti con campi in posizione variabile anzichè fissa) vanno definite le regole di identificazione dinamica dei campi mediante funzionalità FREE-FORM e ANALISI del LAYOUT.
Fase 1. Acquisizione
- Acquisizione locale da scanner
- Acquisizione locale da file .TIF, .JPG, .BMP, .PDF
- Acquisizione locale mediante monitoraggio automatico di una directory
- Acquisizione locale da fax
- Acquisizione da remoto via internet (TCP/IP)
- Impostazione prorità lavorazione lotto*
- Impostazione numero massimo di immagini per lotto*
- Numero licenze postazioni di acquisizione (Recogniform Input Station): ILLIMITATO*
Fase 2. Riconoscimento
-
Operazioni di pre-processing avanzato:
- Filtro colore
- Inversione colore
- Rimozione linee verticali
- Rimozione linee orizzontali
- Rimozione intrusioni
- Rimozione caselle
- Rimozione separatori caratteri
- Rimozione riquadri campi
- Ricostruzione caratteri attraversati
- Rimozione sporco
- Rimozione bordo nero
- Auto orientamento modulo
- Auto allineamento modulo
- Raddrizzamento modulo
- Raddrizzamento locale (singolo campo)
- Smoothing dei caratteri
- Binarizzazione immagini in scala di grigi mediante algoritmi di thresholding dinamico
- Auto identificazione template
- Operazioni di riconoscimento ottico:
- utilizzo motore BCR (Barcode). Velocità: ILLIMITATA
- utilizzo motore ICR (Manoscritto stampatello). Velocità: ILLIMITATA
- utilizzo motore OMR (caselle di marcatura). Velocità: ILLIMITATA
- utilizzo motore OCR (testo stampato/dattioscritto). Velocità: ILLIMITATA
- utilizzo motore OCR-A/B (testo stampato con font OCR-A/B). Velocità: ILLIMITATA
- utilizzo motore MICR-CMC7/E13B (codelines stampate con font MICR CMC7/E13B). Velocità: ILLIMITATA
- utilizzo motore CHR (manoscritto corsivo). Velocità: ILLIMITATA
- utilizzo motore FREE-FORM e ANALISI del LAYOUT. Velocità: ILLIMITATA
Per approfondire le funzionalità FREE-FORM e LAYOUT ANALYSIS clicca qui)
- utilizzo motore FORM IDENTIFICATION. Velocità: ILLIMITATA
 Fase 3. Correzione Fase 3. Correzione
- E.B.V.® (Eye Blow Verification)
- Verifica visuale assistita
- Text- to-Speech integrato
- Trigrammi
- Look-up dinamico
- Collegamento a qualsiasi dbms
- Vocabolari compressi
- Regole di quadratura personalizzabili via script
- Overlay (visualizzazione del modulo ricostruito)
- Numero licenze postazioni di acquisizione (Recogniform Correction Station): ILLIMITATO*
Fase 4. Output
- Trasformazione dati e normalizzazione
- Salvataggio immagini con modalità e directory scelte dall'utente
- Creazione statistiche per workstation, utente, modulo, attività
- Rilascio dati su files:
- .txt, .csv, .xls, .html, .htm, .pdf, .mdb, .tab, .slk, .sylk, .xml, .tsv, .sql, .dbf, .db, pdf ricercabile
- Rilascio dati su database
- Oracle, Interbase, Sybase, SQL Server, Access, ODBC Compatibili, Paradox, dBase, FoxPro, Db2
* caratteristica disponibile solo nella versione Workgroup
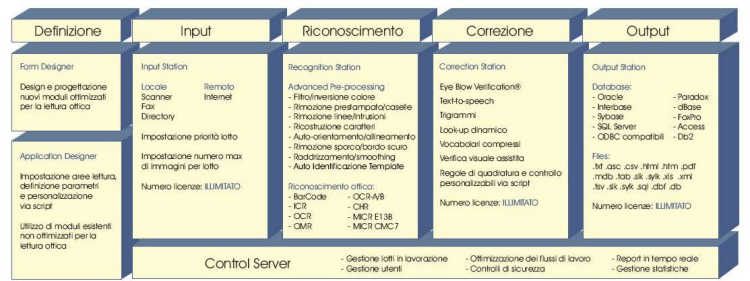
Schema riassuntivo
Vai alla pagina di Recogniform Desktop Reader
Vai alla pagina di Recogniform Workgroup Reader
Vai alla pagina di Recogniform Invoices
Scarica la brochure in formato .pdf (348KB)
Richiedi maggiori informazioni
|
