|
|
|

Motore di riconoscimento CHR per manoscritto corsivo - CHR sdk

Recogniform CHR Engine è il motore di riconoscimento per il manoscritto corsivo sviluppato da Recogniform Technologies SpA che consente di convertire parole e testi scritti a mano in caratteri ASCII. L'acronimo CHR da noi coniato sta per Cursive Handwritten Recognition ed indica appunto la tecnologia di riconoscimento della scrittura manoscritta corsiva "legata", non in stampatello. Sviluppato in collaborazione con prestigiosi laboratori universitari ha richiesto più di 3 anni di ricerca e sperimentazione prima di diventare un prodotto.
Premessa
Esistono due tecnologie di interpretazione del manoscritto corsivo: riconoscimento on-line e riconoscimento off-line.
Il riconoscimento della scrittura on-line serve a riconoscere parole scritte su dispositivi in grado di mettere a disposizione le informazioni spazio-temporali relative ai movimenti della penna effettuati dallo scrivente. In pratica il riconoscimento avviene su dati vettoriali, costituiti dalle coordinate dei tratti d'inchiostro e dai pen-up/pen-down campionati in tempo reale durante la scrittura. Si tratta quindi dell'analisi di una rappresentazione DINAMICA della scrittura.
Il riconoscimento della scrittura off-line serve a riconoscere parole scritte su supporti cartacei in cui è presente la sola immagine del testo da riconoscere. In pratica il riconoscimento avviene su dati raster, costituiti dai soli pixel accesi/spenti ottenuti dalla digitalizzazione del supporto cartaceo mediante scanner. Si tratta quindi dell'analisi di una rappresentazione STATICA della scrittura.
Tramite un PDA o un tablet PC si può sperimentare l'input di testi utilizzando il riconoscimento della scrittura corsiva on line talvolta in esso integrato; tale tecnologia è infatti largamente impiegata in dispositivi che richiedono l'input mediante l'utilizzo di una penna ed una tavoletta grafica o un touch screen. Al contrario, sarà molto improbabile che troviate dei pacchetti software in grado di effettuare il riconoscimento della scrittura off line su immagini e documenti acquisiti da scanner: ciò è dovuto all'intrinseca difficoltà nel riconoscimento off-line di operare su una quantità di informazioni nettamente inferiore rispetto a quelle su cui lavora il riconoscimento on-line.
Architettura
L'architettura del nostro sistema di riconoscimento è costituita da diversi sotto-sistemi specializzati che, a partire dall'immagine della parola da riconoscere, riescono a produrre la sua rappresentazione in termini di caratteri.
Un primo sotto-sistema si occupa del pre-processing dell'immagine, cioè della pulizia e della normalizzazione del tratto di inchiostro.
Successivamente il secondo sotto-sistema si fa carico della sbrogliatura: in pratica si tenta di ricostruire la sequenza dinamica dei tratti d'inchiostro così come sono stati presumibilmente tracciati dallo scrivente. Questa è l'operazione più delicata: il maggiore o minore successo di questa fase, determinato dalla qualità dell'immagine e dallo stile di scrittura utilizzato, decreta la bontà dell'interpretazione finale. A valle del processo di sbrogliatura la parola risulta suddivisa in sequenze di tratti, ognuno dei quali corrisponde alla traccia d'inchiostro prodotta dallo scrivente tra l'istante di tempo in cui viene poggiata la penna sul foglio e l'istante di tempo in cui la penna viene sollevata interrompendo momentaneamente la sequenza di scrittura.
La successiva fase di segmentazione genera dei tratti elementari che corrispondono agli atti motori elementari eseguiti dallo scrivente. Infatti, in accordo agli studi sulla generazione della scrittura corsiva I movimenti complessi necessari per produrre la scrittura corsiva possono essere visti come una composizione di movimenti elementari che corrispondono a forme elementari, chiamate stroke. Tali stroke vengono tracciate una di seguito all'altra e la scrittura risulta fluente a causa della sovrapposizione temporale dei movimenti elementari che producono le stroke. Le stroke rappresentano quindi le primitive di forma che ciascuno scrivente utilizza nel processo di scrittura e rilevanti studi effettuati nel campo della visione hanno mostrato che la curvatura dei tratti gioca un ruolo chiave nella percezione delle forme e della loro composizione. Dal momento che è noto che in corrispondenza dei tratti di connessione tra stroke adiacenti vengono generati cambi di curvatura significativi, il processo di segmentazione posiziona dei punti di taglio in corrispondenza dei tratti di inchiostro nei quali si verificano i cambi di curva più rilevanti, tentando di scartare le variazioni di curvatura spurie comunque generate dai processi di scrittura e di digitalizzazione.

Nella seguente fase di descrizione ciascuna stroke precedentemente identificata dal processo di segmentazione viene etichettata in base al suo cambio di curvatura, opportunamente quantizzato.
La penultima fase, il matching, consiste nel confrontare tratti di inchiostro relativi alla parola da riconoscere con quelli relativi ad un insieme di parole di riferimento di cui è disponibile anche la trascrizione in codice ASCII. In questo modo vengono estratte le sequenze di stroke simili e con esse le possibili interpretazioni.
Infine il sotto-sistema di classificazione produce le possibili interpretazioni della parola andando a considerare tutte le possibili combinazioni dei match ottenuti dalla fase precedente e calcolando contestualmente un livello di affidabilità.
Come si evince l'architettura risulta piuttosto complessa, in virtù della difficoltà del compito da svolgere. In effetti alla base c'è la semplice idea di poter riconoscere delle parole identificandone delle sotto-sequenze mediante il confronto di tratti di inchiostro contenuti in un reference set. Un esempio molto semplicistico è quello di un reference set contenente le parole "problema" e "valore", da cui poter riconoscere le parole "prova", "malore", "prore", "mare", "arma", "roma" e così via.
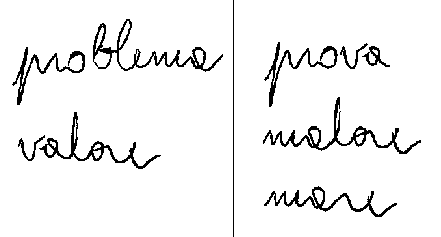
reference set derivati dal reference set
Tuttavia la variabilità nella forma del manoscritto corsivo prodotto da una popolazione di scriventi si traduce nella possibilità che scriventi appartenenti allo stesso gruppo possano usare N grafemi diversi per rappresentare lo stesso N-gramma. In altre parole la variabilità del modo di scrivere è tale che la stessa cosa può essere scritta in modi anche molto diversi tra loro, secondo lo stile di scrittura di ciascuno. Con riferimento all'esempio di cui sopra, se scrivessi le due sillabe della parola "prova" in maniera completamente diversa rispetto alle stesse presenti in "problema" e "valore" potrei non essere in grado di riconoscere correttamente il testo. Da cià deriva la necessità di associare ad ogni grafema il/i possibili N-grammi di riferimento, secondo complessi algoritmi di probabilità congiunte in grado di portare all'interpretazione corretta della parola. In alcuni casi è anche possibile ricorrere all'utiizzo di dizionari contenenti un numero n di parole così da restringere la cerchia di ipotesi di lettura ed accrescere il livello di accuratezza del riconoscimento.
Recogniform CHR Engine è disponibile come motore di riconoscimento opzionale per Recogniform Reader.
Ulteriori Informazioni
Per richiedere maggiori informazioni su Recogniform CHR Engine clicca qui.
Per richiedere maggiori informazioni su Recogniform Reader clicca qui.
Per altre informazioni, si prega di usare la pagina dei contatti.
© 2000-2022 Recogniform Technologies S.p.A. - P.IVA IT02376980781 - Tutti i diritti sono riservati